
In my previous post I described at a high level what it means to build a cloud native application and hopefully gave you an idea of why building applications in the cloud can be different than you may be used to. One thing many cloud native applications have in common is that they are often built using a microservices architecture. But before we talk about microservices lets talk about the types of applications most people are familiar with building today.
Most applications people build today are 3-tier, monolithic applications. What do I mean by monolithic? Basically the entire application is deployed as a single entity. In Java terms this might mean when you deploy your application, you deploy the entire thing in a single WAR or JAR file. The fact that the application is monolithic is not a bad thing, but at some point most applications reach a certain size and gain a certain amount of complexity where the monolith is too hard to understand and is starting to hinder the productivity of the team. At this point the monolith is no longer suited for the cloud (or on premise) and something needs to change.
Enter microservices. At a high level an application that is implemented using a microservices architecture is one that is composed of several (this could be 10s or 100s) completely independent “services” or apps that work together to produce the overall end user experience. Obviously since the term “micro” is used in microservices these services are meant to be small, lightweight, and focus on a single task. How small is small? That is the million dollar question  There is no one measurement that I can give you that determines the correct size of a microservice. Instead it is all about productivity and speed. If a service gets to the point where you feel it is doing too many things and is hard to understand and work with, than it is likely too big and should be split into more than one service.
There is no one measurement that I can give you that determines the correct size of a microservice. Instead it is all about productivity and speed. If a service gets to the point where you feel it is doing too many things and is hard to understand and work with, than it is likely too big and should be split into more than one service.
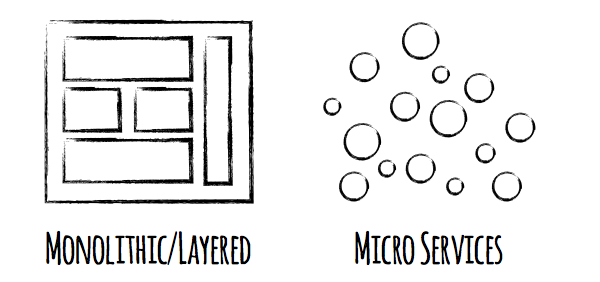
In addition to the small size of the code base, the team that works on each microservice is also small and compact. Each team for each microservice is composed of the developers, testers, product managers, etc. They act completely independent of each other team and each other microservice. This is a very important part of the microservices architecture. Microservices are not only about the technical architecture of your application, but also the architecture of you organization. There is no separate organizations for test, development, and product management. Each microservice is comprised of a team that has people who test, develop, do DevOps, and handles product management. That team focuses on that one service and that one service alone and are the only people responsible for that service.
I always think that looking at concrete examples is a good idea when talking about something new. I have been working on a cloud native application that uses microservices. The idea behind the application is pretty simple. As a developer advocate, I am always giving talks at conferences and people, usually, have questions about the topic I am speaking about. I wanted to make it easier for people to ask questions so I wrote an application that allows you as a speaker to create an entry for a session you are giving and then anyone that attends that session can go to the application select your session and ask a question about the topic you are presenting on. Attendees can ask questions via the application itself or they can text questions from their mobile device. As a speaker you can then reply to whatever questions are asked via the application and the user who asked the question will get a response via email if they submitted the question via the application or via text if they texted the question. The idea is simple and you can imagine it would be easy to implement that application as a traditional 3-tier monolithic app. In fact, that is how it started out, and here is what it looked like.
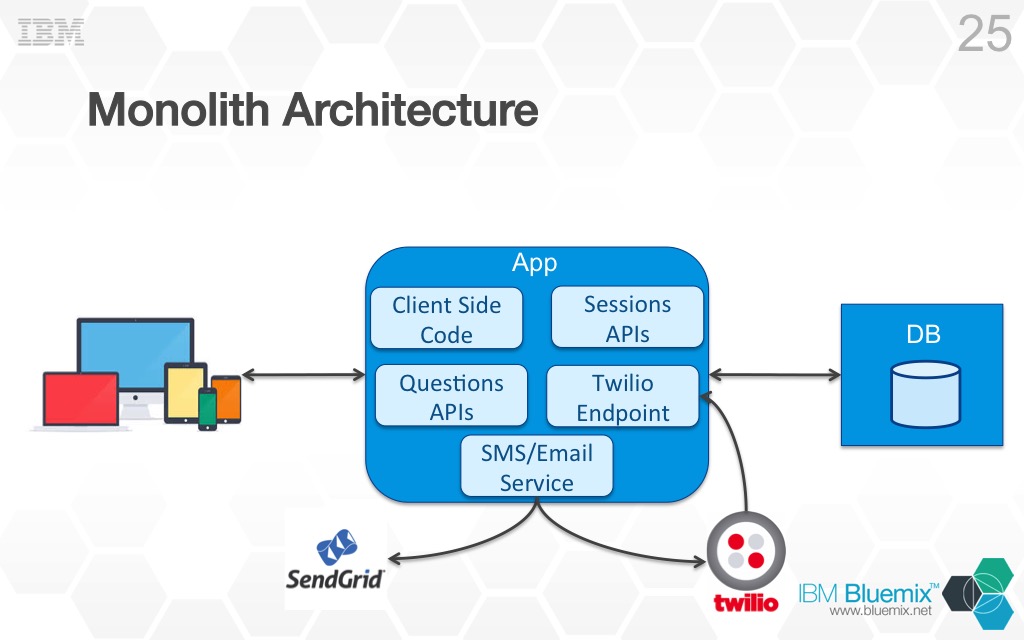
As you can see the monolith (the big blue square in the middle) had a number of components in it. It contained the client side code served to the browser, REST APIs the client side code used, a REST API for Twilio (for texting), and some code which took care of sending the emails/texts for answers. All the details about the sessions and the questions asked during those sessions was stored in a single DB. Like I said, a very traditional application architecture, and when deployed to the cloud it worked fine, no issues.
In fact at this point I would like to bring up an important point. In my own personal opinion (and not everyone agrees with me), I think that for certain types of applications a monolithic architecture will work fine in the cloud. For all the benefits of adopting microservices, one of the drawbacks is complexity (in how all the services works together, not in the individual services themselves). So if your application is simple enough and you are not experiencing some of the problems I have mentioned than it is OK to build a monolithic application and run it in the cloud. However, most production applications are not simple and quickly approach that threshold where the complexity (in the code) and size of the application starts effecting the stability of the application the performance of the team. Since I wanted to explore how I could transition this application to use microservices I decided to break this application apart, but that is not to say that this app the way it was originally architected was bound for failure.
Lets look at a couple of problems that this monolithic architecture could cause in the cloud. First up failure. What happens if there is a problem in the Sessions API component of my application. Maybe it is chewing up a huge portion of the CPU, or maybe it just crashes. What happens to my application?
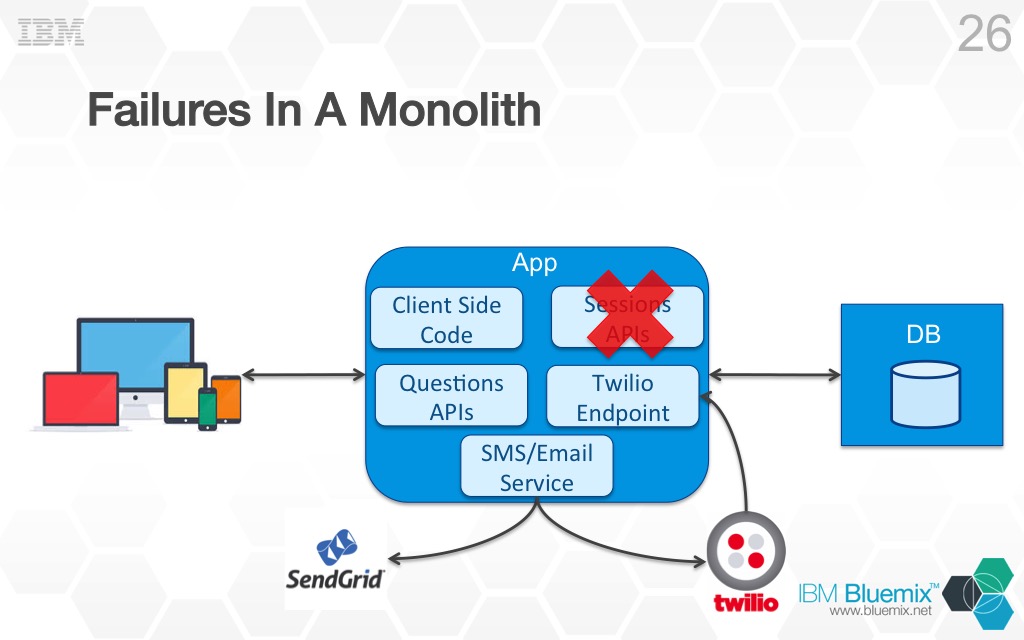
Thats right, pretty the entire application will be effected by this. If it crashes all the other components of my application come crashing down with it. Maybe it is not even a problem with my code, maybe it is the networking or hardware underneath my application provided by the cloud (stuff that is out of my control). Whatever the reason for the problem is, my entire application is unavailable even if there is a problem with just a single component. This makes my application very fragile and is not what we want, fragility is the enemy.
The next problem with the monolithic architecture is scalability. Lets look at what scaling the monolith looks like.
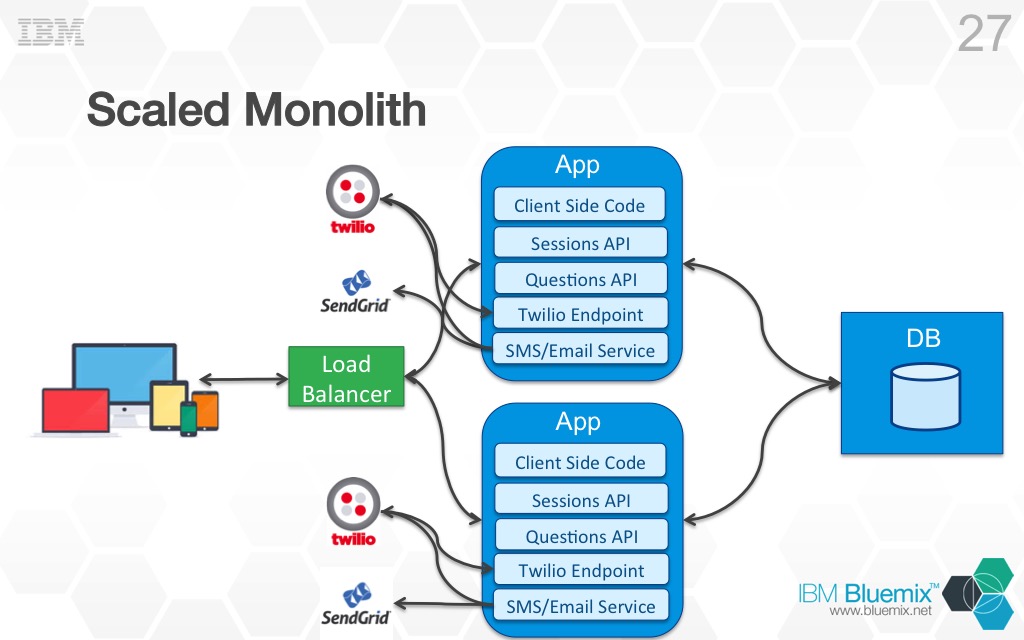
Petty much what you would expect right? Instead of 1 instance of the monolith running, I have 2 instances running with a load balancer sitting infront of both instances routing requests between the two. There is nothing wrong with this configuration, it will work fine. Conceptually though, it is probably not what I really need. In all reality, if I am at the point where I need to scale my application it is more likely that it is just one component of my application that needs to scale. For example, say the Sessions API component is under a lot of load and can’t handle the number of requests being issued to it. Scaling that component horizontally will solve the issue, but since my application is a monolith I can’t just scale that one component I have to scale the entire app. Probably not a big idea when it is just one component of our monolith that needs to scale, but what if I have 2 or 3 components that need to be scaled? Maybe the Sessions API component would be fine with 2 instances but the Questions API component needs 5. My only option is to scale my monolith up to 5 instances even though most of the other component don’t need that many instances. This is a big waste of resources, and in the cloud that means wasted money!
In addition to the problems with monolithic applications described above we also have the problem of working with huge monolithic code bases. Consider when someone new joins the team to work on a monolithic application, how long would it take them to understand how the application works? The answer is a very long time, if ever. I know from experience. I worked on a giant, 25 year old, monolithic application in my previous role at IBM, and I only understood a very small piece of how that application worked and I worked on it for 5 years! Other issues include the time needed to build, test, and deploy monolithic applications. It is incredibly slow and fragile process (remember fragility is the enemy). If you have worked on a monolithic application, you know how painful this process can be. You get to the point where you are ready to release and someone finds a bug in a single small component. This stops everything, everything needs to go through the release process all over again, that is easily a multi-day process. This is just not acceptable when you are looking to be agile and move with speed.
So how does changing the application to a microservices architecture help solve some of these problems? Let take a look at how the application looks once we move to using microservices.
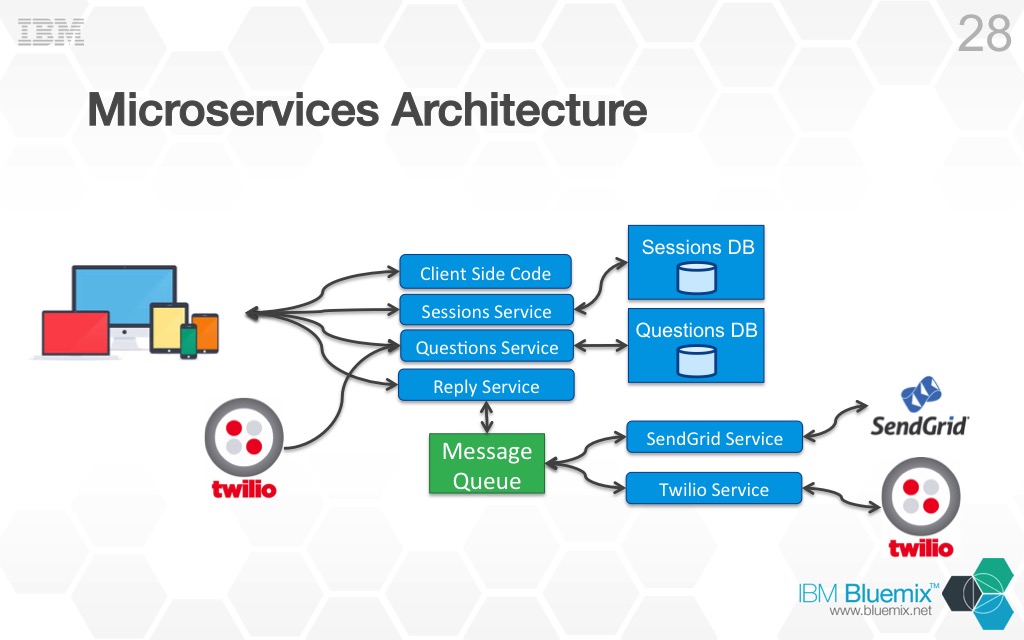
For the most part, what I have done here is take each light blue box from the monlithic architecture and made it its own app, or microservice. The SendGrid and Twillio services were also broken out into separate apps, I will address why I did this later on when we talk about scalabilty. From a fragility point of view, this architecture if much more resilient. Lets take the same example from above where the Sessions Service crashes, hangs, or goes down due to the infrastructure underneath it. In this architecture, if that happens, the client side code will still be served to clients, and the Questions, Reply, SendGrid, and Twilio services all will continue to function as before. Will the app behave perfectly with the Sessions Service unavailable? No. Is it better than if the entire application was down, YES!
What about scalability with this architecture? It is much better than before because I can scale each service independently of the other.
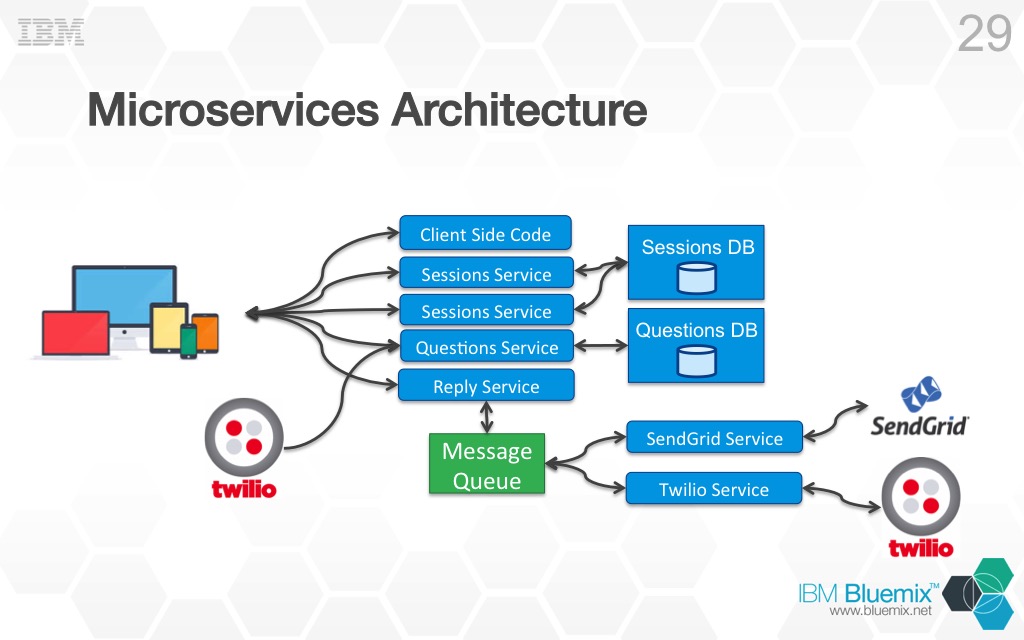
In the above picture you can see I am able to scale the Sessions Service without scaling any other part of the application. The microservices architecture allows me to scale only the components of my application that need it. This is the reason for the changes I made to the SendGrid and Twilio services. These two services are responsible for sending out replies to questions via email or text. As you can imagine it might be easy for them to become overloaded with many speakers replying to questions at once. At the same time it is not important that those replies go out the second the speaker sends them, so in my opinion, this was the perfect place to use a message queue. The reply service receives replies that need to be sent out and just places them in a queue, which is a very quick operation. The SendGrid and Twilio services are more like workers which just take replies out of the queue and sends them along. This allows the reply service to handle much more load and at the same time I can scale the SendGrid and Twilio services up or down essentially creating more or less worked to handle whatever is in the queue.
There is one part of the microservices architecture in the pictures above that I have not addressed yet, and that has to do with the databases. In the monolithic architecture there was a single database, but in the microservices architecture there are 2, one database for the Questions Service and one for the Sessions Service, why? One of the golden rules of microservices is that each service should be independent of each other. If 2 services are sharing the same database than they are not truly independent because changes or problems with the database can effect one or both services. For this reason if a microservice needs to persist data, than it should do so in its own database. This in itself introduces a new set of problems and is one of the reasons why microservices architectures can be more complicated than monolithic architectures. The most challenging problem this introduces is a data consistency problem because you could be having to persist the same data in 2 different databases. The approach that most microservice applications take to solve this problem is to apply the principal of eventual consistency to their data, meaning the data in the different databases may not be consistent for some period of time but eventually it will be. This topic deserves its own blog post so I won’t go into it here, but try searching the “Internets” and I am sure you will find much more information on various approaches to this problem.
What about the code base of the application? Once I split the monolithic application up into microservices I actually created several code bases. Each microservice has its own git repo, its own build pipeline, its own defect tracking system. Remember above where we talked about how each microservice needs to be independent of each other? Well this not only applies to data storage but also source control. If I put all the code for each microservice in a single git repo (which is what I did at first) than changes to that git repo effect all microservices. For example, if for some reason I need to create a branch just to work on a defect in one microservice I end up creating a branch for all microservices. This is not really what I want to do and can have effects on the other services (ie merging).
Since each microservice has a very small footprint from a code point of view, on boarding new developers to work on a microservice is much easier. The smaller code base makes it much easier to learn. In addition I can do releases of each microservice independent of the others. I no longer have the problem of a bug being found at the last minute in a single component that blocks the entire release. If one microservice has a bug we can go back and address that bug while the other microservices continue to move forward unaffected.
Wow that was a lot to take in right? And guess what, we are only part way there! My application’s architecture is certainly better now that it is using microservices but not perfect, there are still one or two problems we need to address. I think I will let everyone digest this blog post first before we dive into part two and address some of these issues.
For more detailed information on microservices I suggest you read Marin Fowlers and James Lewis post on the topic. There are many other resources on the internet that discuss the topic in great detail. If you are one of those people that fancies reading books, I suggest you check out this one on microservices. I haven’t read the whole thing yet, but so far so good in my opinion. There is also a recently released RedBook from IBM on microservices, I have not read this one yet so can’t offer any thoughts on it. In addition to the RedBook there is a nice interview with Constant Contact done by my colleague Carlos M Ferreira where they discuss how Constant Contact is using microservices.
